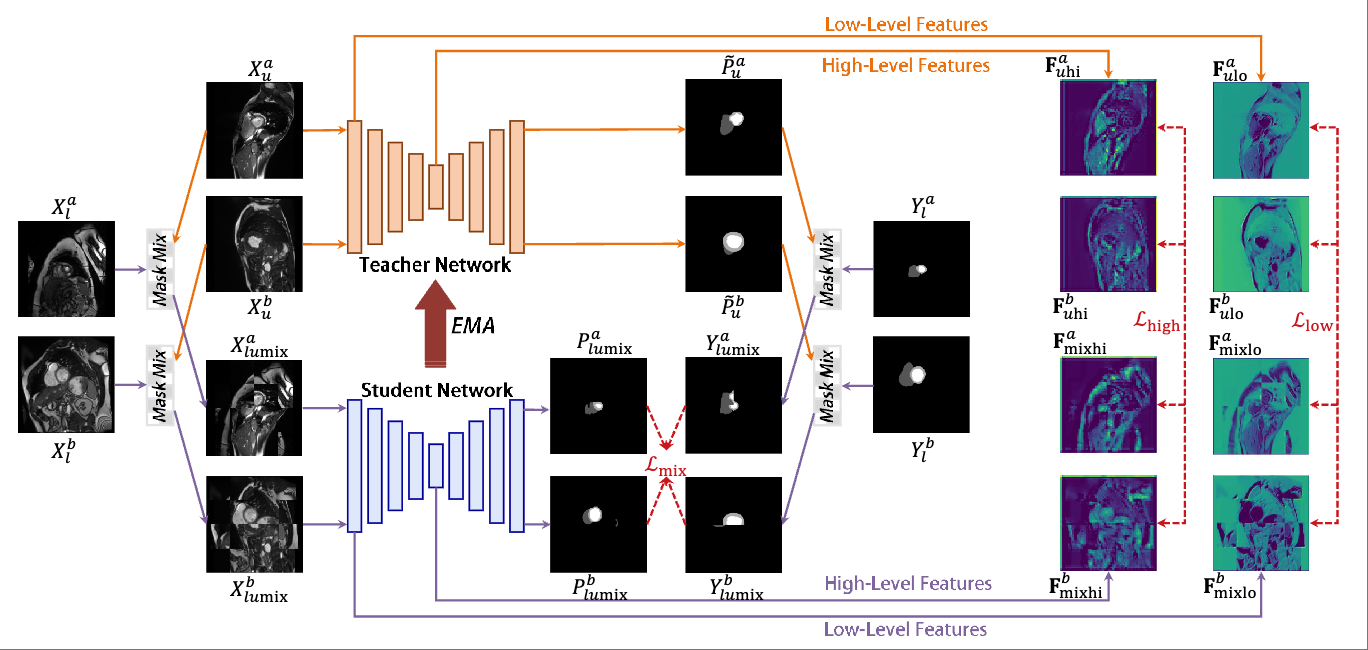
@article{liu2025m,title={M $\^{} 3$ HL: Mutual Mask Mix with High-Low Level Feature Consistency for Semi-Supervised Medical Image Segmentation},author={Liu, Yajun and Zhang, Zenghui and Yue, Jiang and Guo, Weiwei and Li, Dongying},journal={Accepted by MICCAI 2025},url={https://arxiv.org/pdf/2508.03752},year={2025},}
arXiv
Grid-Reg: Grid-Based SAR and Optical Image Registration Across Platforms
Xiaochen Wei, Weiwei Guo, Zenghui Zhang, and 1 more author
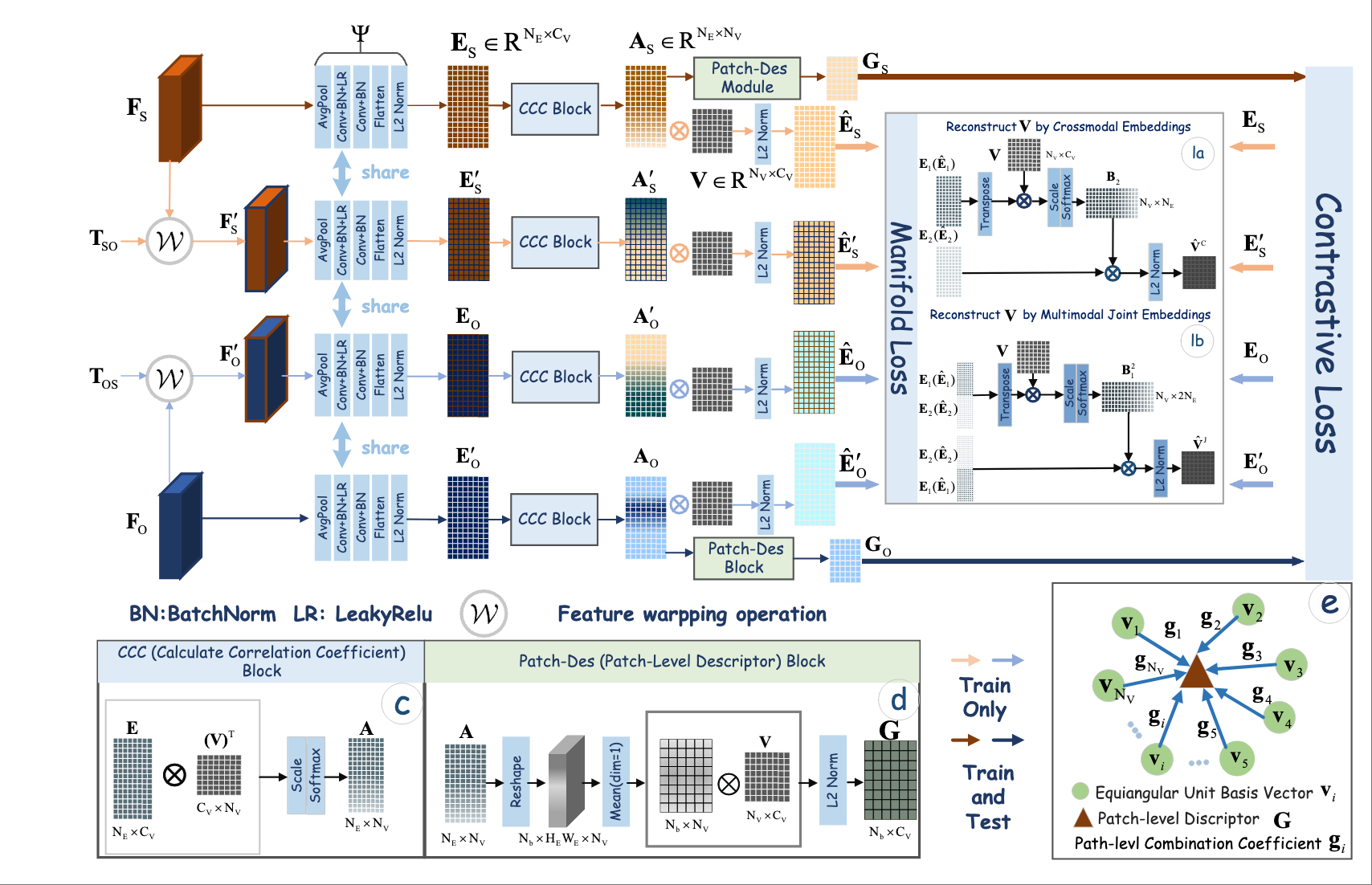
@article{wei2025grid,url={https://arxiv.org/pdf/2508.03752},year={2025},title={Grid-Reg: Grid-Based SAR and Optical Image Registration Across Platforms},author={Wei, Xiaochen and Guo, Weiwei and Zhang, Zenghui and Yu, Wenxian},journal={arXiv preprint arXiv:2507.04233}}
CHI
GenComUI: Exploring Generative Visual Aids as Medium to Support Task-Oriented Human-Robot Communication
Yate Ge, Meiying Li, Xipeng Huang, and 4 more authors
In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025
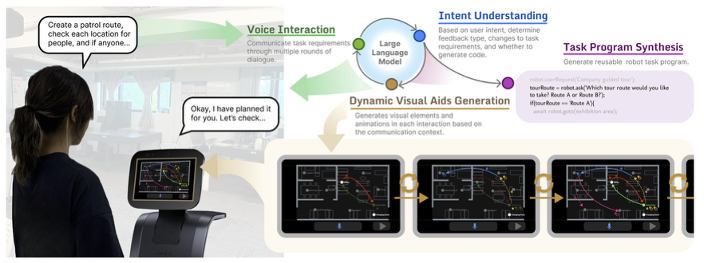
This work investigates the integration of generative visual aids in human-robot task communication. We developed GenComUI, a system powered by large language models (LLMs) that dynamically generates contextual visual aids—such as map annotations, path indicators, and animations—to support verbal task communication and facilitate the generation of customized task programs for the robot. This system was informed by a formative study that examined how humans use external visual tools to assist verbal communication in spatial tasks. To evaluate its effectiveness, we conducted a user experiment (n = 20) comparing GenComUI with a voice-only baseline. The results demonstrate that generative visual aids, through both qualitative and quantitative analysis, enhance verbal task communication by providing continuous visual feedback, thus promoting natural and effective human-robot communication. Additionally, the study offers a set of design implications, emphasizing how dynamically generated visual aids can serve as an effective communication medium in human-robot interaction. These findings underscore the potential of generative visual aids to inform the design of more intuitive and effective human-robot communication, particularly for complex communication scenarios in human-robot interaction and LLM-based end-user development.
@inproceedings{GeCHI2025,author={Ge, Yate and Li, Meiying and Huang, Xipeng and Hu, Yuanda and Wang, Qi and Sun, Xiaohua and Guo, Weiwei},title={GenComUI: Exploring Generative Visual Aids as Medium to Support Task-Oriented Human-Robot Communication},year={2025},isbn={9798400713941},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3706598.3714238},doi={10.1145/3706598.3714238},booktitle={Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems},articleno={433},numpages={21},keywords={Human-Robot Interaction, Robot Programming, Service Robots, Conversational Interaction, Large Language Models, Generative UI},series={CHI '25},}
2024
ECCV
Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning
Yan Li, Weiwei Guo, Xue Yang, and 4 more authors
In 18th European Conference on Computer Vision (ECCV 2024), Milan, Italy, 2024
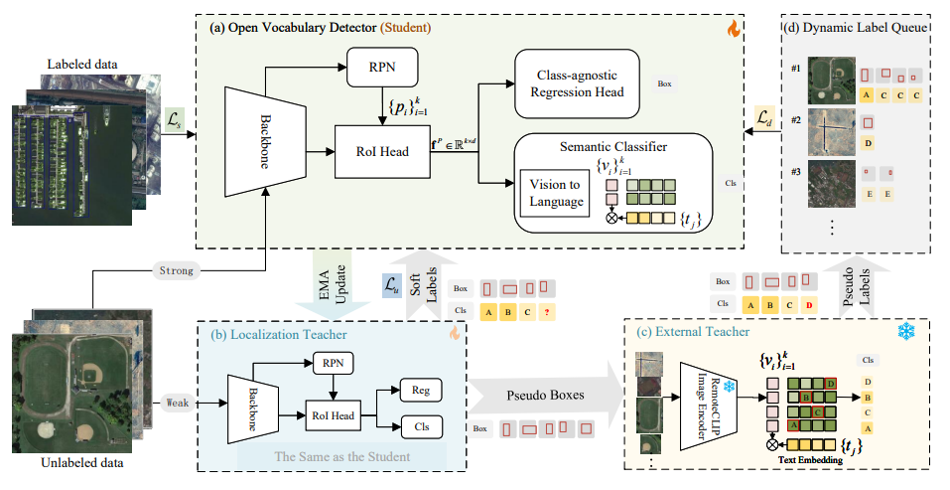
An increasingly massive number of remote-sensing images spurs the development of extensible object detectors that can detect objects beyond training categories without costly collecting new labeled data. In this paper, we aim to develop open-vocabulary object detection (OVD) technique in aerial images that scales up object vocabulary size beyond training data. The performance of OVD greatly relies on the quality of class-agnostic region proposals and pseudo-labetls for novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework following the student-teacher self-learning mechanism employs the RemoteCLIP model as an extra omniscient teacher with rich knowledge. By doing so, our approach boosts not only novel object proposals but also classification. Furthermore, we devise a dynamic label queue strategy to maintain high-quality pseudo labels during batch training. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 46.5% mAP on VisDroneZSD novel categories, which outperforms the state-of-the-art open-vocabulary detectors by 21.0% mAP. To our best knowledge, this is the first work to apply and develop the open-vocabulary object detection technique for aerial images. The code is available at .
@inproceedings{LiyangECCV2024,author={Li, Yan and Guo, Weiwei and Yang, Xue and Liao, Ning and He, Dunyun and Zhou, Jiaqi and Yu, Wenxian},title={Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning},year={2024},url={https://doi.org/10.1007/978-3-031-73016-0_25},doi={10.1007/978-3-031-73016-0_25},booktitle={18th European Conference on Computer Vision (ECCV 2024)},pages={431–448},numpages={18},location={Milan, Italy},}
IEEE GRSM
Optical and Synthetic Aperture Radar Image Fusion for Ship Detection and Recognition: Current state, challenges, and future prospects
Zenghui Zhang, Limeng Zhang, Juanping Wu, and 1 more author